Module 1: Introduction
History Time
The following events led to the eventual creation of the Scala Language:
- Mid-1980 Functional languages in research (e.g., Scheme, ML, Miranda)
- Type inference, lazy evaluation, and higher-ranked types.
- 1987- 1999 Development of Haskell by Peyton’Jones et al.
- A pure, lazy, functional language that includes typoeclasses and features monads.
- Odersky words on higher-ranked types (incorporated in GHC).
- 1999 - 2001 Development of Funnel by Odersky.
- 1996 Sun Microsystem releases Java 1.0 by James Gosling
- 1997 Pizza language by Martin Odersky ad Philip Wadler.
- Superset of Java: translates to Java source as an intermediate representation.
- Parametric polymorphism (generics), algebraic types (case classes), and higher-order functions.
- 1998 Bracha, Odersky, Stoutmire and Wadler publish GJ at OOPSLA featuring generics.
- Type erasure as a consecuence.
- 2000 Sun Microsystems adopts GJ compiles as
javacin JDK 1.3 - 2004 Sun Microsystems realeses Java 1.5 incorporating generics from GJ.
- 2004 Odersky publish the Scala Language based on the prev work of Funnel and Pizza.
- 2006 Scala 2.x with many improvements.
For a more detailed explaination see Dan Rosen conference called Scala > Java.
Why OOP became popular?
According to Martin Odersky in his Scala with Style conference:
Because of the representation of concepts and the things you could do with that.
The first OOP languages (Simula 96 and Smalltalk) allowed a way to execute a fixed API with an unknown implementation. This generated a rising popularity of the OO paradigm.
Object oriented design (SOLID):
- S - Single Responsibility Principle
- O - Open-closed Principle
- L - Liskov substitution principle
- I - Interface segregation principle
- D - Dependency Inversion Principle
What about FP?
Functional programming has lots of methodological advantages:
- Fewer errors
- Better modularity
- Higher-level abstractions
- Shorter code
- Increases developer productivity (easy to reason)
Nonetheless, a “cultural shock” has maintained the FP approach underground.
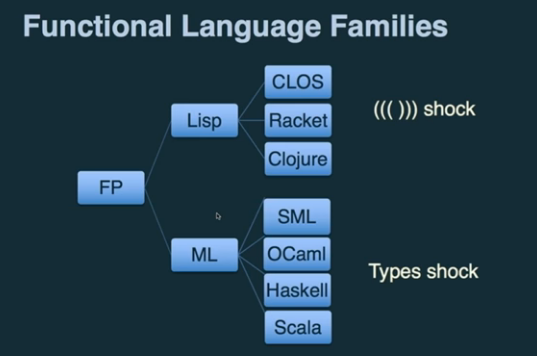
This was true, until software development reached certain level of complexity derived from:
- Multicore, parallel programming
- Async, asynchronous events
- Cloud computing, distributed environments
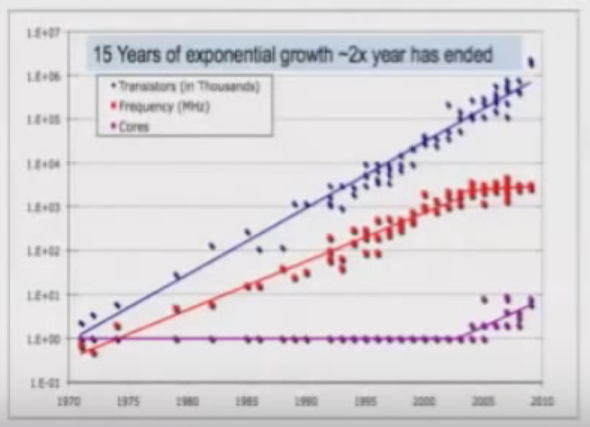
Several languages and frameworks use locks/threads that don’t scale. Therefore, the need of better and safer abstractions.
The essence of functional programming offered a viable solution in the form of immutable transformation of values instead of stepwise modification of mutable state.
Can FP and OOP be combined?
Of course. According to the official website Scala is a:
Combination of object oriented and functional programming in a high-level and static typed language.
What else is Scala?
Scala was created by Martin Odersky at the EPFL in 2004. The current version (2.12.7) is maintained by Scalacenter and Lightbend.
Scala is object-oriented
Pure object-oriented language; every value is an object and every operation is a method call. Types and behaviour of objects are describes by classes and traits. Class composition is done via a mixin-based mechanisms that replaces multiple inheritance.
Scala is functional
In Scala every function is a value. It supports higher-order functions, nesting, recursion, and currying.
def reverse[A](list: List[A]): List[A] = {
def tailRecReverse(result: List[A], prependOps: (List[A], A) => List[A])(current: List[A]): List[A] = current match {
case Nil => result
case head :: tail => tailRecReverse(prependOps(result, head), prependOps)(tail)
}
val reverseOp = tailRecReverse(List.empty[A], (xs: List[A], x: A) => x +: xs) _
reverseOp(list)
}
(unnecessarily complex example)
Scala is statically typed… with type inference!
Scala has an strongly typed system that supports type inference.
val courseName = "Introduction"
def square(x: Int) = x * x
Scala has different runtimes

Scala interops with Java
Scala has seamless interoperability with the Java Ecosystem. According to the official site:
Scala classes are ultimately JVM classes. You can create Java objects, call their methods and inherit from Java classes transparently from Scala.
Scala has lightweight syntax
Example: assume we want to know the number of underage persons on a group.
Java Code
import java.util.ArrayList;
public class Example {
public class Person {
public final String name;
public final int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
}
public void count() {
ArrayList<Person> peopleList = new ArrayList<Person>();
peopleList.add(new Person("A", 15));
peopleList.add(new Person("B", 20));
peopleList.add(new Person("C", 17));
peopleList.add(new Person("D", 22));
Person[] people = new Person[4];
people = peopleList.toArray(people);
ArrayList<Person> minorList = new ArrayList<Person>();
ArrayList<Person> adultList = new ArrayList<Person>();
for (int i = 0; i < people.length; i++)
(people[i].age < 18 ? minorList : adultList).add(people[i]);
System.out.println(minorList.size());
System.out.println(adultList.size());
}
public static void main(String[] args) {
Example example = new Example();
example.count();
}
}
Scala Code
object Example extends App {
class Person(val name: String, val age: Int)
val people = Array(
new Person("A", 15),
new Person("B", 20),
new Person("C", 17),
new Person("D", 22))
val (minors, adults) = people partition (_.age < 18)
println(minors.length)
println(adults.length)
}
Scala Parallel Code
object Example extends App {
class Person(val name: String, val age: Int)
val people = Array(
new Person("A", 15),
new Person("B", 20),
new Person("C", 17),
new Person("D", 22))
val (minors, adults) = people.par partition (_.age < 18)
println(minors.length)
println(adults.length)
}
Scala empowers concurrency and distribution
You can use data-parallel operations on collections, actors for concurrency/distribution or futures for asynchronous programming. Scala was build with concurrency and parallelism is mind.
val x = Future { someExpensiveComputation() }
val y = Future { someOtherExpensiveComputation() }
val z = for (a <- x; b <- y) yield a * b
for (c <- z) println("Result: " + c)
println("Meanwhile, the main thread goes on!")
Scala in the industry
According to Lightbend:
Scala has taken over the world of Fast Data, which is what some are calling the next wave of computation engines […] (ability to process event streams in real time).
Case Studies
- Twitter - New tweets per second record
- Paypal - Blows past 1 billion transactions per day
- Walmart - Boost conversion by 20%
- Samsung - Real time data platform for wearables
And more!
Relevant big-data open source projects
Scala has a relevant impact on Apache Spark, Apache Kafka, Apache Flink, Akka Streams and more!
Why is Scala in such position?
According to Dean Wampler, traditional big-data tools are inefficient and hard to implement.
Consider a typical word-count application.
A solution using MapReduce with Java should look similar to:
import org.apache.hadoop.*;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWriter> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer strTokenizer = new StringTokenizer(value.toString());
while (strTokenizer.hasMoreTokens()) {
word.set(strTokenizer.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reduces<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Interable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
resut.set(sum);
context.write(key, result);
}
}
}
Using Spark with Scala:
import org.apache.spark.sql._
object WordCount extends App with Context {
import spark.implicits._
final case class WordCount(word: String, count: Long)
val readPath = "path/to/input/file"
val writePath = "path/to/output/file"
val data: Dataset[String] = spark.read.textFile(readPath)
val wordCount: Dataset[WordCount] = data
.flatMap(_.split("""\s+""")).map(_.toLowerCase.replaceAll("[^A-Za-z0-9]", "")).filter(_.length > 1)
.groupByKey(identity).count().map({case (w, c) => WordCount(w, c)})
.sort($"count".desc)
wordCount.coalesce(1).write.csv(writePath)
}
See the complete example here.
It’s evident that the FP abstractions exposed over the Spark API provide a more easy-to-use API. Moreover, the actual performance of the Spark Engine vs MapReduce can be 100x faster.
Noel Welsh and Dave Gurnell in their book Scala with cats explain that:
- Monoids are used in Spark to perform parallel work on each partition and combine the results in a single node.
- Distributed systems use commutative replicated data types (CRDTs) to guarantee eventual consistency and to support reconciliation.
How to get started?
Installing Scala
We can use the standalone scala compiler.
$ sudo apt install openjdk-8-jdk
$ wget https://downloads.lightbend.com/scala/2.12.6/scala-2.12.6.deb
$ sudo dpkg -i scala-2.12.6.deb
Change the .deb for .msi (Windows) or .tgz (Mac).
Or see the official documentation for more options.
(Students using Windows 10 are encouraged to install WSL)
Hello, World!
Create a helloworld.scala file with the following content:
object HelloWorld {
def main(args: Array[String]): Unit =
println("Hello, World!")
}
In the command line:
$ scala helloworld.scala
$ scalac helloworld.scala && scala HelloWorld
Using the Scala REPL
You can launch the Scala REPL by simply typing scala in the command line.
- Scala tool for evaluation expressions (similar to ipython).
- Has build-in tab completion.
- Load scala files using
:load file.scala - Paste mode using
:paste - Get expression types with
:type - Exit with
:q
scala> println("This is the Scala REPL")
This is the Scala REPL
scala> def sum(x: Int, y: Int): Int = x + y
sum: (x: Int, y: Int)Int
scala> :type sum _
(Int, Int) => Int
scala> :load helloworld.scala
Loading helloworld.scala...
defined object HelloWorld
scala> HelloWorld.main(Array.empty)
Hello, World!
Scala Scripts with Ammonite
Scala scripts are lightweight files containing Scala code that can be directly run from the command line.
Install by running:
$ sudo sh -c '(echo "#!/usr/bin/env sh" && curl -L https://github.com/lihaoyi/Ammonite/releases/download/1.2.1/2.12-1.2.1) > /usr/local/bin/amm && chmod +x /usr/local/bin/amm' && amm
Create a file named fibonacci.sc containing:
import scala.annotation.tailrec
def fibonacci(n: Int): List[BigInt] = {
def recFibo(n: Int): BigInt =
if (n < 2) 1 else recFibo(n - 1) + recFibo(n - 2)
if (n <= 0) List[BigInt]() else 0 :: (0 until n).toList.map(recFibo)
}
def tailRecFibonacci(n: Int): List[BigInt] = {
@tailrec
def recFibo(n: Int, a: BigInt = 0, b: BigInt = 1): BigInt = n match {
case 0 => a
case 1 => b
case _ => recFibo(n-1, b, a+b)
}
if (n < 0) List[BigInt]() else (0 to n).toList.map(recFibo(_))
}
@main
def main(i: Int = 5): Unit = {
println(s"Fibonacci sequence for i=$i : ${tailRecFibonacci(i).toString}")
}
Run the script with amm fibonacci.sc 10
We can use Ammonite to import other scripts or Ivy Dependencies.
Create a file fibosum.sc containing:
import $file.fibonacci
import scala.util.Try
def fibosum(i: Int)( fib: Int => List[BigInt]): BigInt =
fib(i).foldRight(0: BigInt)(_ + _)
@main
def main(i: Int = 5, tailrec: Boolean = true): Unit = {
val fiboSum = fibosum(i) _
val res: Option[BigInt] = Try(
if (tailrec) fiboSum(fibonacci.tailRecFibonacci _)
else fiboSum(fibonacci.fibonacci _)).toOption
println(s"The sum of the fibonacci sequence for i=$i is $res.")
}
Run the script with (you may need to sudo apt install time):
time amm fibosum -i 40 -tailrec falsetime amm fibosum -i 40 -tailrec true
Any difference? Implementation matters!
Scala projects with SBT
SBT is the most popular build tool for Scala Projects.
Some relevant features:
- Scala-based build definition!
- Continuous compilation and testing.
- Package and publish.
- Mixed Scala/Java projects.
- Scala REPL with project classes and dependencies on classpath.
- Parallel task and test execution.
You can install SBT by running:
$ echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2EE0EA64E40A89B84B2DF73499E82A75642AC823
$ sudo apt update && sudo apt install sbt
$ sbt about
See more installation instructions here.
Let’s create a minimal project:
$ mkdir hello-world && cd hello-world
$ mkdir -p src/main/scala/example
$ mkdir -p src/test/scala/example
$ touch build.sbt
Create a source file at src/main/scala/example/Hello.scala
package example
object Hello {
val message = "Hello, World!"
def main(args: Array[String]): Unit =
println(message)
}
Now we can:
- Compile the project with
sbt compile - Compile and run with
sbt run.
Add dependencies in the build.sbt file:
ThisBuild / scalaVersion := "2.12.7"
ThisBuild / organization := "com.example"
lazy val hello = (project in file("."))
.settings(
name := "Hello",
libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % Test,
)
Now we can add tests in src/test/scala/example/HelloSpec.scala
package example
import org.scalatest.{FlatSpec, Matchers}
class HelloSpec extends FlatSpec with Matchers {
"The Hello object" should "contain a message starting with 'Hello'" in {
assert(Hello.message startsWith "Hello")
}
}
Run tests with sbt test
We can use the Scala REPL with the dependencies and classes defined in our project with sbt console
scala> import example.Hello
import example.Hello
scala> Hello.message
res0: String = Hello, World!
For more information and features see sbt by example.
Giter8 templates
Current sbt versions allow to create new build definitions from a template using the new command. Giter8 contains the most popular templates.
$ sbt new {template-name}
scala/scala-seed.g8- seed template for Scalaakka/akka-quickstart-scala.g8- akka quickstartholdenk/sparkProjectTemplate.g8- spark template
And more.
IntelliJ Idea IDE
IntelliJ Idea is one of the bests IDEs with Scala support. We’ll be using this IDE for the Nanodegree.
Students are encouraged to donwload the Jetbrains Toolbox App.
We can import SBT Projects using IntelliJ
$ sbt new scala/scala-seed.g8
$ idea . &
Consider looking at the talk Effective Scala development in IntelliJ Idea by Mikhail Mutcianko for more information regarding tips & tricks.
Personal Assignment!
- Use the
scala/hello-world.g8giter8 template to create a project. - Run the project using the
sbt runcommand form the CLI. - Use IntelliJ Idea to edit the project to print “Howdy, World!” instead of “Hello, World!”
Study Material
Talks and Conferences
- Working Hard to Keep It Simple by Martin Odersky
- Scala with Style by Martin Odersky
- Scala, the Simple Parts by Martin Odersky
- Plain Functional Programming by Martin Odersky
- Why Big Data Needs to be Functional by Dean Wampler
- Spark, the Ultimate Scala Collection by Martin Odersky
- What’s Different in Dotty by Martin Odersky
Other online resources
- Scala 2.12 language specification official archive
- Getting Started with Scala official archive
- The Origins of Scala by Bill Venners and Frank Sommers
- Goals of Scala by Bill Venners and Frank Sommers
- Scala’s Type System by Bill Venners and Frank Sommers
- Scala’s Prehistory official archive
- Why Scala? by Martin Odersky
- Programming in Scala by Martin Odersky